Healthcare data anonymization is the process of removing identifying details from patient information to protect privacy while enabling research and analytics. Here's what you need to know:
- Why It Matters: Anonymization protects patient privacy, ensures HIPAA compliance, and allows data to be used for research without legal hurdles.
- Methods: Techniques include generalization, suppression, data masking, perturbation, k-anonymity, and differential privacy. Each balances privacy and data utility differently.
- Challenges: Balancing privacy with data usefulness, complying with evolving laws like HIPAA, and managing costs and resources.
- Tools: AI-driven platforms like Censinet RiskOps™ automate anonymization workflows, risk assessments, and compliance checks.
Cyberattacks on healthcare are rising, making anonymization a critical defense. A well-designed anonymization pipeline ensures sensitive data is protected while remaining useful for analysis. Start by identifying sensitive data, applying appropriate techniques, and using tools to streamline the process.
De-Identifying Healthcare Data for Research
sbb-itb-535baee
What Is Healthcare Data Anonymization?
Healthcare data anonymization involves removing identifiers from Protected Health Information (PHI) to ensure it can be used for research, policy analysis, and analytics without violating privacy. Once the data is de-identified, it no longer qualifies as PHI under HIPAA regulations[1]. This process is critical for balancing data utility with privacy protection.
The U.S. Department of Health and Human Services highlights the importance of anonymization in protecting individual privacy while enabling secondary data use:
"The process of de-identification, by which identifiers are removed from the health information, mitigates privacy risks to individuals and thereby supports the secondary use of data." – U.S. Department of Health and Human Services[1]
HIPAA outlines two approaches for de-identification:
- Safe Harbor Method: This method involves removing 18 specific identifiers, such as names, Social Security numbers, email addresses, photographs, and geographic details smaller than a state.
- Expert Determination Method: A qualified statistical expert assesses and confirms that the likelihood of re-identification is extremely low. Organizations must document the analysis and results to prove compliance with HIPAA standards[1].
It's important to distinguish anonymization from pseudonymization. While pseudonymization replaces identifiers with tokens and allows for potential re-identification, anonymization ensures that re-identification is impossible. This makes anonymization the preferred choice for high-risk activities like medical research or sharing data with third parties[2].
Why Healthcare Organizations Need Data Anonymization
With cyber threats on the rise and data playing a larger role in healthcare, anonymization has become a critical tool. It protects patients' privacy while enabling essential medical research. Healthcare organizations must balance their responsibility to safeguard data with the need to comply with legal standards and support advancements in medicine. By anonymizing data, they can meet legal standards, build trust, and facilitate research without compromising privacy.
Meeting HIPAA and Legal Requirements
The Health Insurance Portability and Accountability Act (HIPAA) provides a clear path for using de-identified health data. Once data is properly anonymized, it’s no longer classified as Protected Health Information (PHI), meaning the HIPAA Privacy Rule no longer applies to its use or disclosure [1][3]. This allows organizations to share data freely without requiring individual patient consent for every instance.
To achieve this, organizations can either follow the Safe Harbor method - removing 18 specific identifiers - or use the Expert Determination approach, which involves expert validation that the risk of re-identification is minimal. Both methods ensure compliance while reducing the likelihood of misuse. Beyond meeting regulations, these practices also strengthen patient trust by demonstrating a proactive approach to privacy.
Protecting Patient Privacy and Building Trust
Anonymization shows patients that their privacy is a priority, even as their data is used for broader healthcare insights. By adhering to established frameworks like Safe Harbor or Expert Determination, organizations reassure patients that their information is handled responsibly. Additional measures, such as data use agreements and regular certifications, further reduce re-identification risks and boost confidence in data security [1].
Enabling Research and Data Sharing
De-identified data eliminates many regulatory hurdles, making it easier to use for secondary purposes like research and policy development. For instance, anonymized datasets can fuel comparative studies, evaluate healthcare policies, or support life sciences innovation - all without requiring individual patient consent for each use [1][3].
Organizations can also customize datasets to balance detail and privacy. For example, one dataset might include detailed geographic data but generalized age information, while another might reverse this balance. Both Safe Harbor and Expert Determination methods aim to keep re-identification risks "very small", but it’s crucial to document processes and reassess regularly as technology evolves [1].
Methods for Anonymizing Healthcare Data
Healthcare organizations use various techniques to protect patient identities while maintaining the usefulness of their data. Choosing the right method depends on how much detail is needed and the acceptable level of re-identification risk. Some methods focus on simplifying or removing data, while others rely on mathematical approaches. Together, these techniques create a solid foundation for anonymization that supports both privacy laws and practical data use.
Generalization and Suppression
Generalization reduces the precision of data. For example, instead of showing an exact birth date, the data might only display the year or an age range, such as 45–49. Similarly, a full ZIP code like 90210 could be shortened to just the first three digits (902). This approach lowers the chance of identifying someone. For instance, using only a birth year, gender, and a 3-digit ZIP code makes a person unique in just 0.04% of U.S. cases, compared to over 50% when exact birth dates and full ZIP codes are included [1].
Suppression goes a step further by removing sensitive details or even entire records. HIPAA's Safe Harbor method mandates removing 18 specific identifiers, such as names, Social Security numbers, and smaller geographic details, to comply with privacy rules. However, this can result in a significant loss of useful information, which may limit the dataset's value for research [1].
Data Masking and Perturbation
Data masking hides sensitive details to prevent re-identification. A common method is hashing, where data is converted into a fixed-length string using a cryptographic algorithm. This process is one-way, meaning the original data cannot be retrieved. Perturbation, on the other hand, makes small, deliberate changes to the data - like slightly altering ages or dates - to protect privacy while preserving overall trends. Striking the right balance is key: too much alteration reduces the data's value, while too little may not sufficiently protect privacy.
k-Anonymity and Differential Privacy
k-Anonymity ensures that each individual in a dataset is indistinguishable from at least k–1 others in key attributes. For example, setting k = 5 means each record matches at least four others in certain fields. Differential privacy takes a more advanced approach by introducing controlled mathematical noise to the data. This allows researchers to identify broad patterns without exposing specific individuals.
Tokenization and Pseudonymization
Tokenization replaces sensitive information with random tokens stored in a secure system. Only authorized users can reverse this process. Pseudonymization works similarly by swapping private identifiers with fake ones. HIPAA allows organizations to assign unique codes to de-identified records for re-identification later, as long as the codes aren’t derived from patient information and the re-identification process is secure. These methods are particularly useful for tracking patients across datasets without exposing their identities.
"Both methods, even when properly applied, yield de‑identified data that retains some risk of identification. Although the risk is very small, it is not zero, and there is a possibility that de‑identified data could be linked back to the identity of the patient..." - HHS Office for Civil Rights [1]
The U.S. Department of Health and Human Services emphasizes that while these techniques significantly reduce re-identification risks, no method is foolproof. Organizations must continually balance privacy with data usefulness and adapt their strategies to keep up with technological advancements.
How to Build a Healthcare Data Anonymization Pipeline
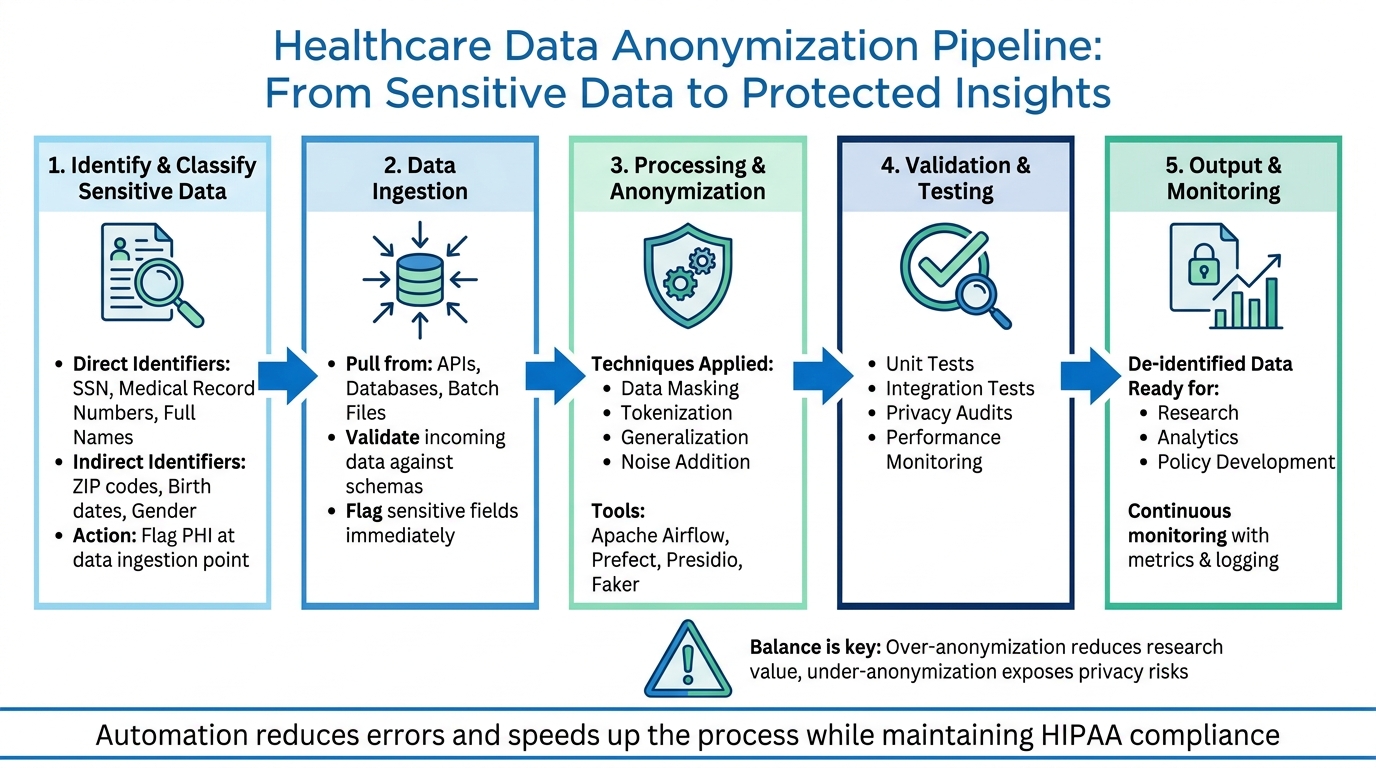
Healthcare Data Anonymization Pipeline: 5-Step Implementation Process
Creating a pipeline to anonymize healthcare data is all about transforming sensitive information into a format that protects privacy while preserving its usefulness for analysis. A properly designed pipeline automates the process, minimizes human error, and ensures consistent privacy safeguards across datasets.
Identifying and Classifying Sensitive Data
The first step in anonymization is figuring out what data needs protection. This means identifying and categorizing information that qualifies as Protected Health Information (PHI) under HIPAA. Direct identifiers, like Social Security numbers, medical record numbers, and full names, are the most obvious candidates for protection. However, indirect identifiers - such as ZIP codes, birth dates, and gender - can also pose risks when combined, potentially revealing someone's identity.
To manage this, classify PHI right at the point of data ingestion. Validate incoming data against expected schemas and flag sensitive fields immediately. Once identified, these classifications must be consistently applied throughout the pipeline to ensure no sensitive data slips through the cracks.
Pipeline Steps: Ingestion, Processing, and Validation
After identifying sensitive data, the next step is to build a pipeline that handles data ingestion, processing, and validation in a structured way. This ensures compliance with HIPAA standards and protects patient privacy.
- Ingesting Data: Pull data from sources like APIs, databases, or batch files. During this stage, validate incoming data and flag any PHI for special handling.
- Processing Data: Use techniques such as masking, tokenization, generalization, or noise addition to anonymize PHI. These methods should align with the data’s classification to protect privacy while retaining its analytical value. Tools like Apache Airflow or Prefect can orchestrate workflows, while libraries like Presidio or Faker can handle the anonymization tasks.
- Validating and Monitoring: Test the pipeline with unit tests, integration tests, and privacy audits to ensure it functions correctly. Use metrics and logging to monitor performance and quickly identify any anomalies.
Avoid hardcoding rules so the pipeline can adapt to new data formats or privacy regulations as they evolve. Automation is key here - it reduces errors and speeds up the process. However, finding the right balance is crucial. Over-anonymizing data can strip away details essential for research, while under-anonymization can leave privacy vulnerabilities exposed.
Tools and Platforms for Healthcare Data Anonymization
When selecting tools for healthcare data anonymization, it's crucial to go beyond simple redaction. Modern tools now use AI to identify Protected Health Information (PHI) and Personally Identifiable Information (PII) across electronic medical records, clinical notes, and research datasets. These AI-driven systems can detect both direct identifiers - like Social Security and medical record numbers - and indirect identifiers that, when combined, could expose patient identities. What sets the best tools apart is their ability to maintain contextual awareness, ensuring that PHI embedded in complex clinical notes is identified without accidentally removing critical information [4][5].
But anonymization is just one piece of the puzzle. Healthcare organizations also face broader challenges in managing risks tied to sensitive patient data. This includes vetting third-party vendors, ensuring research teams and Institutional Review Boards stay compliant, and moving away from outdated manual processes - like spreadsheet-based risk assessments - which become unmanageable as the number of vendors and privacy regulations grow. To address these complexities, platforms tailored specifically for healthcare data management are essential.
One such platform is Censinet RiskOps™, which automates risk management processes for anonymization workflows across the entire healthcare data lifecycle. Designed exclusively for the healthcare sector, it taps into a network of over 50,000 vendors to streamline risk assessments. This ensures all vendors meet rigorous security standards before they gain access to patient information. As Matt Christensen, Sr. Director GRC at Intermountain Health, explains:
"Healthcare is the most complex industry... You can't just take a tool and apply it to healthcare if it wasn't built specifically for healthcare" [6].
The platform's AI capabilities further enhance efficiency by automating vendor questionnaires, validating evidence, and generating detailed risk summary reports. Terry Grogan, CISO at Tower Health, highlighted the platform's impact on resource allocation:
"Censinet RiskOps allowed 3 FTEs to go back to their real jobs! Now we do a lot more risk assessments with only 2 FTEs required" [6].
For organizations managing anonymization pipelines, this translates to faster onboarding of analytics vendors, research collaborators, and cloud service providers, all while ensuring tight control over who accesses patient data and how it's safeguarded.
Censinet RiskOps™ also provides cybersecurity benchmarking and real-time risk monitoring, moving away from static reviews to deliver continuous insights. This dynamic approach enables teams to identify gaps in data protection, secure necessary resources, and align anonymization workflows with HIPAA requirements and best practices. Its centralized command center offers a comprehensive view of risks across patient data, clinical systems, and research operations. This visibility allows leadership to pinpoint areas for improvement, ensuring anonymization efforts stay aligned with evolving privacy regulations.
Best Practices for Anonymizing Healthcare Data
Conducting Regular Risk Assessments
Cyber threats are always evolving, and sticking to annual audits just isn’t enough anymore. Instead, organizations should turn to AI tools equipped with risk assessment capabilities to simulate re-identification attacks. These tools can help pinpoint weak spots in anonymization methods and flag potential risks early on. Using automated risk assessment tools can streamline this process by instantly identifying vulnerabilities in data handling. For example, indirect identifiers like diagnosis codes, ZIP codes, or visit dates might seem harmless, but they can still reveal patient identities if not handled carefully. Testing and refining anonymization methods regularly ensures these vulnerabilities are addressed before they become a problem, keeping compliance strong and consistent.
Staying Compliant with HIPAA and Other Standards
Meeting legal requirements is just as important as managing risks. Under HIPAA, data is only considered de-identified if it no longer contains any markers that could identify someone [4][5]. This means addressing all 18 HIPAA identifiers without fail. One effective approach is standardizing placeholders - for instance, replacing names with [name], dates with [date], and locations with [location]. This method helps maintain compliance while still allowing the data to be useful for audits and research [5]. AI-driven anonymization tools can further assist by keeping detailed audit trails, documenting exactly how each identifier is handled. For organizations also subject to GDPR, anonymization supports the principle of Data Minimization by ensuring only the essential personal data is collected [4].
Working Across Teams for Consistent Implementation
Anonymization isn’t something one department can handle alone - it requires teamwork. IT, compliance, and medical teams need to collaborate closely to ensure both legal and research requirements are met [4][5]. For instance, involving healthcare providers in the process can help verify that anonymized data still holds clinical value while also identifying and removing indirect identifiers [5]. This “human-in-the-loop” approach adds an extra layer of oversight, catching issues that automated systems might miss and ensuring the data is both secure and practical.
Common Challenges in Healthcare Data Anonymization
While there are effective methods for anonymizing data, applying them in real-world scenarios comes with its own set of hurdles.
Maintaining Data Usefulness While Protecting Privacy
Balancing privacy with data usability is no easy task. Anonymization changes data permanently to prevent re-identification, but this often comes at the cost of losing critical details needed for research [2]. Organizations face tough decisions: should they use de-identified data, which carries some re-identification risks, for internal purposes? Or should they opt for fully anonymized data, which is safer but may lack the depth needed for external research? A misstep here could either compromise privacy or render the data less effective for its intended purpose.
Each anonymization method - data masking, pseudonymization, differential privacy, and k-anonymity - offers different strengths and weaknesses. Choosing the wrong one can leave data vulnerable or make it less useful for research. For instance, tokenization paired with a token vault is better suited for scenarios where re-identification might be needed later, unlike one-way hashing, which is irreversible [2]. Organizations must align their methods with their goals: de-identification is ideal for internal analytics, while full anonymization is necessary for sharing data externally or conducting medical research [2].
These challenges are further complicated by the need to adapt to shifting legal requirements and financial constraints.
Keeping Up with Changing Privacy Laws
Healthcare organizations operate under a patchwork of privacy regulations that are constantly evolving. For example, HIPAA compliance requires meeting one of two standards for de-identification: the "Safe Harbor" method, which removes 18 specific identifiers, or the "Expert Determination" method, which requires statistical evidence that the risk of re-identification is minimal [2][3]. As Jason Vogel from Marcum explains:
"The result of these two privacy approaches [anonymization and de-identification] differs in one major aspect: de-identified data leaves the possibility of re-identification of the data" [2].
Ensuring compliance with these standards is no small feat, especially when additional frameworks like GDPR come into play. One practical approach is to use time-limited certifications for expert determination. This avoids the need for constant reassessment every time technology or data environments change, helping organizations stay compliant without overburdening their resources [3].
Legal compliance is just one piece of the puzzle. Organizations also have to contend with operational and financial limitations.
Working Within Budget and Resource Limits
Implementing robust anonymization measures can be costly and labor-intensive, especially for organizations with limited resources. Manual methods like traditional data masking require significant effort, but automation can ease this burden [7]. By automating the identification and masking of Personally Identifiable Information (PII) and electronic Protected Health Information (ePHI), organizations can cut down on labor and speed up processes [7].
AI-driven tools and synthetic data generation offer more affordable ways to handle sensitive data. Federated learning, for example, allows models to be trained locally, reducing the need to move data and lowering infrastructure costs [7]. For simpler needs, the Safe Harbor method provides a standardized, checklist-based approach, while Expert Determination offers more flexibility for tailoring data utility to specific research goals [3]. Keeping clear documentation of which fields contain PHI can also streamline the de-identification process, saving time and reducing unnecessary redaction [3].
Conclusion
Safeguarding patient privacy through healthcare data anonymization isn't just a regulatory requirement under HIPAA - it's a critical step in protecting sensitive information. This guide has walked through key methods like generalization, data masking, k-anonymity, and differential privacy, alongside practical strategies to navigate common challenges. The numbers are staggering: with healthcare data expected to hit 2,314 exabytes by 2025 and 89% of organizations reporting PHI breaches in 2024, the urgency for effective anonymization has never been greater [8].
The importance of rigorous anonymization is backed by real-world evidence. When done right, anonymization not only preserves the usefulness of data but also significantly reduces the risk of breaches. Yet, only 28% of organizations feel confident in their anonymization efforts. Tools like Censinet RiskOps™ offer a way to bridge this gap. By automating vendor audits, streamlining third-party risk assessments, and enabling collaborative PHI risk management, Censinet empowers healthcare organizations to implement the strategies discussed in this guide while minimizing exposure to risk.
To stay ahead, start by auditing your data pipeline. Identify where sensitive information flows, choose the right anonymization techniques, and ensure compliance gaps are addressed. Solutions like Censinet RiskOps™ provide ongoing validation, foster collaboration across teams, and offer continuous monitoring to keep your systems secure. The stakes are high: non-compliance penalties are projected to reach $6.9 billion in 2024, while organizations with strong anonymization practices save an average of $3.3 million in breach-related costs [8][9]. Don't wait - fortify your data anonymization strategies now.
FAQs
How do I choose between Safe Harbor and Expert Determination?
When deciding between Safe Harbor and Expert Determination, it's all about finding the right balance between maintaining data usefulness and protecting privacy.
Safe Harbor is a straightforward and budget-friendly option. It involves removing 18 specific identifiers to de-identify data, which makes it easier to implement. However, this method often sacrifices data detail, limiting its usefulness for more complex analysis.
On the other hand, Expert Determination allows for keeping more detailed information intact. This approach relies on a professional's assessment of re-identification risks, offering greater flexibility. But it does come with added complexity and the need for specialized expertise.
In general, Safe Harbor works well for routine, low-risk data sharing. Meanwhile, Expert Determination is better suited for research or in-depth analytics where detailed data is essential, all while staying HIPAA-compliant.
What’s the fastest way to test re-identification risk before sharing data?
The fastest way to assess re-identification risk is by leveraging tools designed to estimate how easily anonymized data can be traced back to individuals. These tools focus on quasi-identifiers such as ZIP codes, birth dates, and gender. Pairing these precautions with well-defined data-sharing policies helps ensure a thorough and efficient evaluation of risks before sharing healthcare data.
What documentation should we keep to prove HIPAA-compliant de-identification?
Organizations need to keep detailed records of the methods used for de-identification, alongside risk assessments and related policies. This includes documenting compliance with HIPAA's de-identification standards, whether by Safe Harbor or Expert Determination methods. Maintaining such records provides clear evidence of regulatory adherence.
