In healthcare IT, threat detection helps keep care running when cyber events hit. If you find attacks early, you can cut downtime, limit spread, and get key systems like EHRs, PACS, pharmacy tools, and medical devices back online sooner.
Here’s the short version:
- Prevention is not enough. Hospitals still deal with legacy systems, old software, and connected devices that are hard to secure.
- Detection shrinks attacker dwell time. That gives teams time to lock accounts, isolate systems, and stop spread before care is hit.
- The main goal is continuity of care. Good detection can help avoid ambulance diversion, delayed procedures, and long paper downtime.
- Coverage needs to span five areas: network, endpoints, identity, cloud/SaaS, and medical devices.
- The metrics that matter most are MTTD, MTTR, and RTO. Lower detection and response times usually mean less disruption.
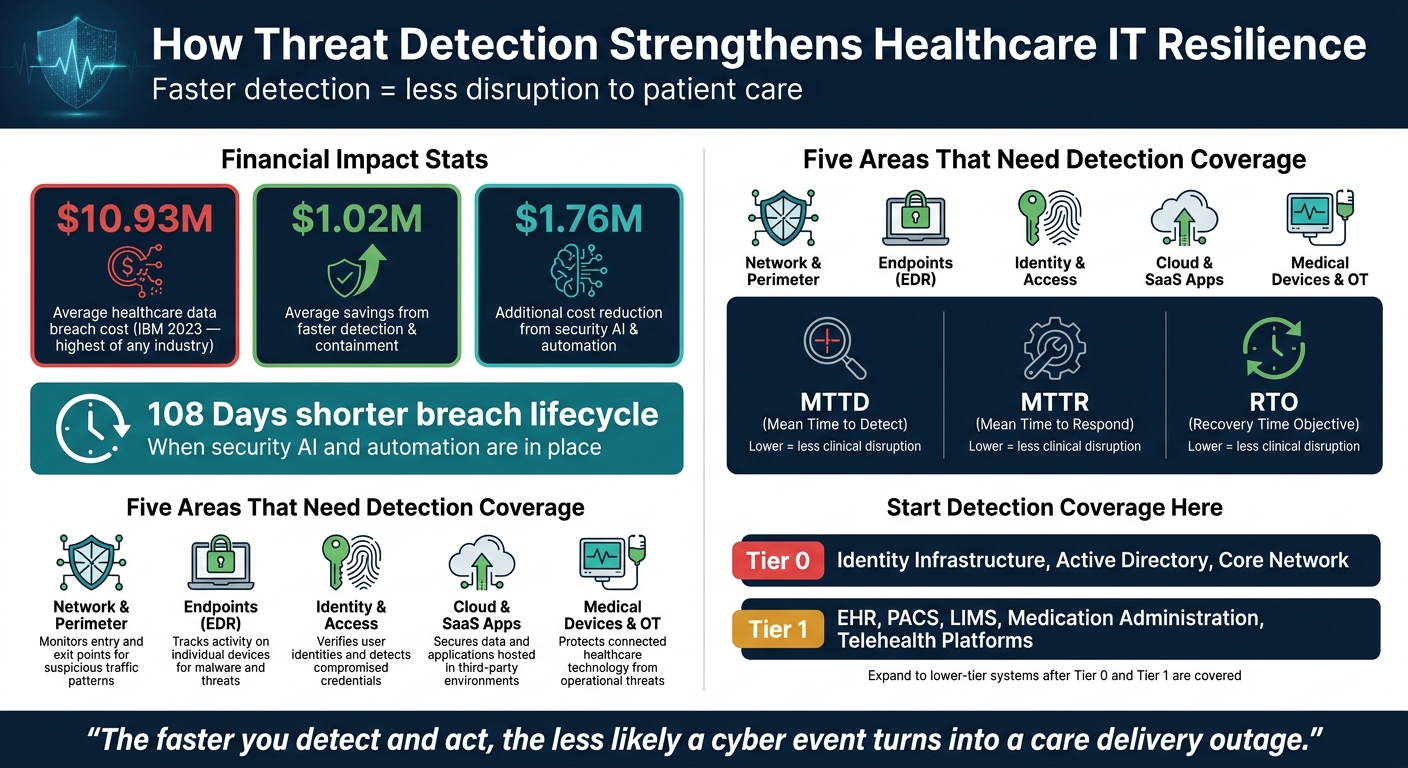
- Automation helps. IBM found healthcare breaches averaged $10.93 million, while faster detection and containment cut costs by $1.02 million. Security AI and automation lowered breach costs by $1.76 million and shortened breach lifecycles by 108 days.
- Healthcare teams need guardrails. Auto-isolating an office laptop is one thing. Cutting off a patient-care system is another.
- Implementation starts with governance and asset tiers. Focus first on Tier 0 and Tier 1 systems like identity, EHR, PACS, LIMS, and medication platforms.
- Risk data should drive priorities. Vendors, shared services, cloud apps, and older medical devices often need the most attention.
If I boil the article down to one idea, it’s this: threat detection is not just about finding bad activity - it helps keep patient care moving.
| Focus area | What it does for resilience |
|---|---|
| Network monitoring | Finds lateral movement early |
| Endpoint detection | Stops malware before it spreads |
| Identity monitoring | Flags stolen accounts and privilege misuse |
| Cloud/SaaS visibility | Spots odd logins and risky API activity |
| Medical device monitoring | Watches devices that can’t run agents |
| SIEM/XDR + automation | Speeds triage and containment |
I’d frame the rest of the article around one plain point: the faster you detect and act, the less likely a cyber event turns into a care delivery outage.
Healthcare Threat Detection: Key Metrics & Financial Impact
Downtime in Healthcare is Fatal: Achieving Resilience in Health & Life Sciences with John Fokker
sbb-itb-535baee
How Threat Detection Improves Resilience in Healthcare IT Systems
Good threat detection cuts the blast radius and helps keep care moving. When teams catch an issue early, they have a much better shot at stopping a short event from turning into a multi-day outage, paper downtime, or ambulance diversion. IBM's 2023 Cost of a Data Breach report found that healthcare had the highest average breach cost at $10.93 million, and that faster detection and containment reduced losses by $1.02 million on average. That starts with visibility across every layer where attacks can get in, move around, or stay hidden.
Where Healthcare IT Environments Need Detection Coverage
Healthcare IT is messy by nature. Systems connect across hospitals, clinics, cloud apps, remote access tools, and medical devices. So detection coverage has to match that sprawl.
The five areas that need detection coverage are:
| Domain | What to Monitor | Why It Matters |
|---|---|---|
| Network & Perimeter | Internet gateways, VPN concentrators, inter-site links | Limits attacker movement before critical systems are affected |
| Endpoints (EDR) | Nursing station workstations, physician laptops, shared clinical workstations, on-premises servers | Detects malware, exploit chains, and suspicious process behavior |
| Identity & Access | Active Directory, Azure AD, privileged access management systems, SSO integrations into EHR and pharmacy | Reveals account takeover, privilege escalation, and service account abuse |
| Cloud & SaaS Apps | Cloud EHR modules, patient portals, telehealth platforms, billing systems | Spots misconfigurations, anomalous logins, and suspicious API activity |
| Medical Devices & OT | Infusion pumps, imaging modalities, physiologic monitors | Baselines normal traffic and flags deviations on devices that can't run agents |
Medical device environments need extra care. A lot of them still run older operating systems, and many can't support EDR agents. That's where passive network monitoring comes in. It uses mirrored traffic to baseline device behavior and flag anomalies without installing agents or getting in the way of care.
Coverage, on its own, isn't enough. It has to show up in resilience outcomes you can measure.
Resilience Metrics That Show Detection Is Working
The goal isn't to pile up alerts. It's to cut dwell time and limit disruption. In healthcare, the metrics that matter most are MTTD, MTTR, incident frequency, containment before lateral movement or data exfiltration, and EHR downtime. When MTTD and MTTR go down, clinical disruption and downtime usually get shorter too.
IBM also found that security automation and AI-assisted detection lowered breach costs by $1.76 million and shortened breach lifecycles by 108 days. That's a clear financial and operational case for putting money into detection that speeds up discovery and response.
| Detection Capability | Resilience Outcome |
|---|---|
| Continuous network monitoring | Faster detection of lateral movement; reduced blast radius |
| Behavior-based analytics (UEBA) | Earlier identification of insider threats and compromised accounts |
| EDR on critical endpoints | Rapid containment of malware before it reaches EHR or PACS |
| Identity threat detection | Reduced risk of large-scale compromise via stolen credentials |
| Medical device/OT monitoring | Maintained availability of life-sustaining and diagnostic systems |
| Centralized telemetry (SIEM/XDR) | Correlated alerts that accelerate incident triage and response |
Use these metrics to see where detection coverage is thin and where response needs to get tighter next. In practice, that usually comes down to continuous monitoring, centralized telemetry, and response plans built for healthcare segmentation.
Core Threat Detection Capabilities Healthcare IT Leaders Should Prioritize
Continuous Monitoring, Centralized Telemetry, and Behavior-Based Detection
Once coverage is in place, the next step is simple: turn visibility into faster containment.
That starts with centralized telemetry across endpoints, identity systems, cloud workloads, and medical devices. When teams feed that data into a central SIEM or XDR, analysts can connect related signals across systems instead of chasing alerts one by one. The payoff is direct: lower MTTD and less time to contain an incident.
From there, behavior-based analytics helps teams sort actual threats from background noise. Signature-based detection only catches attack patterns that are already known. Behavioral analytics works differently. It builds a baseline for normal activity across users, devices, and systems, then flags activity that falls outside that pattern.
That matters in healthcare, where odd behavior can be the first sign that something is off. A nurse account pulling thousands of records in an hour. A CT scanner connecting to an unknown IP. A privileged account suddenly using admin rights it almost never touches. Those are the kinds of signals that User and Entity Behavior Analytics (UEBA) is built to spot. It becomes even more useful for assets that can't run EDR.
Behavior-based detection can also catch ransomware early. Signs like rapid file encryption, shadow copy deletion, or backup process termination may show up before the attack spreads to EHR servers or imaging systems.
Automated Triage and Segmentation-Aware Response
Detection only helps when teams can triage alerts and contain threats fast.
Automated triage gives analysts more context right away by adding asset criticality, clinical impact, vulnerabilities, and network location to each alert. That helps the highest-risk events move to the top first. Faster triage lowers MTTR and cuts down on clinical disruption. Automated playbooks can then take action without waiting on manual review, such as:
- Isolating a compromised endpoint
- Blocking a malicious domain
- Triggering step-up authentication for a suspected account
In healthcare, though, automation needs guardrails. Isolate admin workstations freely; require approval before isolating ICU or other patient-care systems. That balance keeps response fast where the risk is lower and more careful where patient care is on the line.
Detection also needs to match the way healthcare networks are split up. These environments usually separate clinical and enterprise segments, including third-party risk considerations, including ICU, imaging, lab, corporate IT, and guest Wi-Fi. Detection rules should reflect those boundaries. If cross-segment traffic breaks policy, like medical devices reaching administrative networks, that should trigger immediate containment built for that segment.
A Step-by-Step Plan to Implement Threat Detection for Resilience
You can think of threat detection as more than a set of tools. It has to become part of how the organization runs day to day. That means tying monitoring, analytics, and response into one clear operating model.
Start With Governance, Asset Criticality, and Healthcare-Specific Use Cases
Start with governance before you write a single detection rule. Put an executive-approved cyber resilience charter in place that links threat detection to patient safety and continuity of care. That step matters. If the program is framed only as a security project, it can drift away from clinical priorities fast.
Ownership should sit with a cross-functional steering committee that includes the CISO, CIO, CMIO or clinical leadership, compliance/privacy, and key operational leaders. That group keeps the work centered on care continuity, not just technical controls. Use a RACI model to spell out who owns rule creation, alert triage, incident command, clinical communication, and containment approvals.
Next, build one asset inventory that pulls data from the CMDB, endpoint management tools, cloud inventories, and medical device management systems. Then classify each asset with a criticality-based tiering model.
- Tier 0 includes identity infrastructure and core network components, such as Active Directory and identity providers
- Tier 1 includes EHR, PACS, LIMS, medication administration, and telehealth platforms
Begin detection coverage with Tier 0 and Tier 1 assets first. After that, expand into lower-tier systems.
Once that asset view is in place, define detection use cases around healthcare threats that behave differently in practice. For each use case, map the impacted assets, needed log sources, detection logic, severity, linked playbook, and validation steps.
- Ransomware: Monitor rapid encryption, shadow copy deletion, and abnormal SMB activity
- Unauthorized access: Monitor impossible travel, record-access spikes, and off-hours privileged logins
- Vendor compromise: Monitor remote-access anomalies, unauthorized configuration changes on medical devices or clinical apps, and unusual exfiltration from third-party hosted applications
Integrate Detection With Incident Response, Recovery, and Testing
Detection has to connect straight into incident response. A high-severity alert, like ransomware on an EHR server, should automatically open a prioritized incident ticket. No waiting around. No manual handoff if you can avoid it.
Each alert type should map to a response playbook with clear triage steps, containment options, evidence collection tasks, communication paths, and criteria for downtime activation. In a hospital, that last part is huge. Every playbook should show when teams need to shift to paper workflows or manual administration so care can keep moving.
Recovery should also use detection outputs inside business continuity and disaster recovery workflows. If an EHR compromise is confirmed, that should trigger both the cyber playbook and the clinical downtime procedures. Restoration should include backup validation, recovery staging in a test environment, and post-restoration monitoring.
You also need to test the plan. Run scenario-based tabletop exercises at least once a year using realistic events, such as ransomware coming in through a vendor's remote support session, a compromised clinician account accessing thousands of patient records, or malware affecting part of a connected infusion pump fleet. Bring in security, IT operations, biomedical engineering, compliance, clinical leadership, and communications for each exercise.
After each session, complete an after-action review and update the rules and playbooks based on what you learned. Then feed those findings into risk reviews so you can decide where detection coverage should expand next. This process is often supported by real-time portfolio risk management to ensure enterprise-wide visibility.
Measure Performance and Refine Over Time
Track monthly trends and report quarterly progress in a way that ties back to clinical outcomes. Over time, the goal is to see clear movement across each key metric.
| Resilience Metric | Baseline (Pre-Program) | Mature State (12–24 Months) |
|---|---|---|
| Mean Time to Detect (MTTD) | Improving | Consistently low |
| Mean Time to Respond (MTTR) | Improving | Consistently low |
| Critical asset monitoring coverage | Partial coverage of Tier 0/1 systems | Full Tier 0 and Tier 1 coverage |
| False positive rate | Declining | Significantly reduced |
| Incidents detected by automated tooling | Increasing | Higher percentage of high-severity events |
| Unplanned EHR downtime from cyber events | Declining | Lower downtime hours |
| Containment before lateral movement | Inconsistent | Consistent for high-severity events |
Annually, reassess the asset criticality model and the threat landscape. New cloud services, telehealth growth, and newly deployed device types can change where the biggest risks sit. Use those updated priorities to guide third-party vendor risk management, application, and device risk reviews.
Using Risk Management Data to Strengthen Detection and Resilience
Once detection is in place, risk data should shape where coverage expands next. Start by using that data to decide where detection needs to be strongest first. The aim isn't broader monitoring for its own sake. It's faster detection of the risks most likely to disrupt care.
Prioritize High-Impact Risks Across Third Parties, Applications, and Medical Devices
Common high-risk areas include EHR integrations, legacy medical devices, and shared services like identity providers and VPNs. Each one calls for a different detection approach.
For unmanaged or legacy medical devices - infusion pumps, bedside monitors, CT and MRI systems - network-based detection and passive device profiling are often the most practical choices. For high-risk SaaS apps, use identity logs, database activity where available, and user behavior analytics to flag large exports or unusual access. For shared services that many teams depend on, use high-confidence alerts for configuration changes, failed logins, and new device registrations, then tie those alerts straight to rapid response playbooks.
Vendor impact scope - the number of sites, beds, or encounters affected by a vendor compromise - should help set monitoring priority. If a vendor has broad impact and low security maturity, that vendor should get enhanced monitoring, including access anomaly detection and vendor-specific incident playbooks, even without a past incident record. [1][2]
Peer benchmarks can also help separate what's common from what's missing. Compare your program against peers and frameworks like NIST CSF and HICP to spot where detection coverage falls behind. Then turn those gaps into clear monitoring and alerting actions: add EDR, increase network analytics, tighten identity alerting, or expand passive device monitoring. [2]
When those findings sit in one place, it's much easier to turn risk data into detection priorities.
How Censinet RiskOps Supports Resilience-Focused Detection Planning
Censinet RiskOps™ centralizes third-party and enterprise risk assessments and benchmarking, which helps healthcare organizations prioritize detection around the vendors, applications, and devices that matter most to clinical operations. Risk data aggregated in the platform gives security and IT teams a clearer view of where to focus telemetry, tune alerts, and set response priority across PHI-handling systems, clinical applications, connected medical devices, and supply chain partners.
Conclusion: Threat Detection Is a Practical Investment in Healthcare Resilience
The message in this guide is simple: detection turns visibility into resilience. Faster detection cuts damage. Containment reduces disruption. That’s why detection should be managed as a core resilience control, not treated like a separate security tool.
What matters most is the result: reduced dwell time, less operational disruption, and faster recovery. Those outcomes should be tracked through MTTD, MTTR, and RTO and reported to clinical and executive leadership alongside uptime goals.
The next step is focus. Use risk data to decide where detection should go first, especially where operational exposure is highest. When security teams know which vendors, applications, and devices carry the most risk, they can point telemetry and alerting where it matters most.
Treat detection as an operational control, fund it like a core control, and measure it against clinical outcomes. When detection works, care continues.
FAQs
Why isn’t prevention alone enough in healthcare IT?
Prevention alone doesn’t cut it in healthcare IT. Advanced threats can still get through, which is why teams need real-time detection and response.
That matters for three big reasons: it helps limit damage, protects patient safety, and keeps day-to-day operations running.
Which systems should hospitals prioritize for threat detection first?
Hospitals should start with high-risk systems like EHR servers, medical IoT devices, and core infrastructure that handles PHI.
In plain terms: begin with the systems that store sensitive data and matter most for patient care.
How can automation improve response without risking patient care?
Automation can cut response times by kicking off immediate, targeted actions the moment a threat shows up. That can mean isolating a compromised device, disabling a suspicious account, or blocking malicious traffic. The goal is simple: contain the threat fast while letting unaffected systems keep running.
When patient safety is on the line, it makes sense to roll out automation in stages, not all at once. Pair it with human oversight and clear protocols so teams can check each response, fine-tune what works, and catch problems early before extending those actions into life-critical environments.
Related Blog Posts
- From Reactive to Threat Intelligence-Driven Cybersecurity
- How Incident Response Automation Improves Healthcare Security
- From Reactive to Proactive: How Modern Risk Assessors Are Transforming Organizational Resilience
- How Healthcare Organizations Lost Access to Patient Records for 15 Hours - And What Happens Next
